
Subtotal $0.00

At its core, data classification is the process of organising data into categories based on its sensitivity, value, and regulatory requirements. It's about answering three fundamental business questions: What data do we have? Where is it stored? And how critical is it to our operations?
This foundational process is the cornerstone of any effective information security and data governance strategy. It allows an organisation to apply appropriate levels of protection to the right data, ensuring that sensitive intellectual property isn't treated with the same low level of security as a public marketing brochure. Without it, you're essentially flying blind, unable to prioritise security efforts or manage risk effectively.
Understanding Data Classification and Its Business Impact
Think of it like managing a physical office. You wouldn’t leave sensitive client contracts or employee records sitting on an open shelf next to company newsletters. You would instinctively lock them in a secure filing cabinet, with access strictly limited to authorised personnel. Data classification applies that same common-sense principle to your digital assets, creating a structured framework for protecting information in a world of sprawling servers, cloud storage, and SaaS applications.
Without this framework, risk management becomes a guessing game. An organisation with terabytes of unstructured information has no clear way to allocate its security budget. Every file, from an internal team lunch memo to a database of customer financial records, is treated with the same security posture. This not only leaves your most valuable assets—your "crown jewels"—dangerously exposed but also wastes resources protecting data that has little to no value.
Why Data Classification Is a Strategic Imperative
Implementing a data classification framework is not just an IT task; it’s a core business strategy that directly impacts security, compliance, operational efficiency, and cost management. Once you have a clear understanding of your data landscape, you can make informed, risk-based decisions that drive tangible business value.
The real-world benefits include:
- Enhanced Security Posture: By identifying and prioritising your most sensitive data, you can focus security controls and budget where they will have the greatest impact, significantly reducing the risk of a high-impact data breach.
- Streamlined Regulatory Compliance: Regulations like GDPR, CCPA, and HIPAA are built on the principle of data accountability. Classification is the essential first step to demonstrating that you know where personal or regulated data resides and that you are protecting it appropriately.
- Optimised Cost Management: A classification process helps identify Redundant, Obsolete, and Trivial (ROT) data. Eliminating this digital clutter frees up expensive storage, simplifies backups, and reduces overall infrastructure management costs.
- Improved Decision-Making: When business leaders have a clear, accurate map of the company's data assets, they can leverage that information more effectively for strategic planning, operational improvements, and competitive analysis.
The Foundational Levels of Classification
Most organisations can achieve significant risk reduction with a simple, three- or four-tiered classification model. The key is to maintain clarity and simplicity. An overly complex system with too many levels creates confusion and low adoption rates among employees, ultimately defeating the purpose.
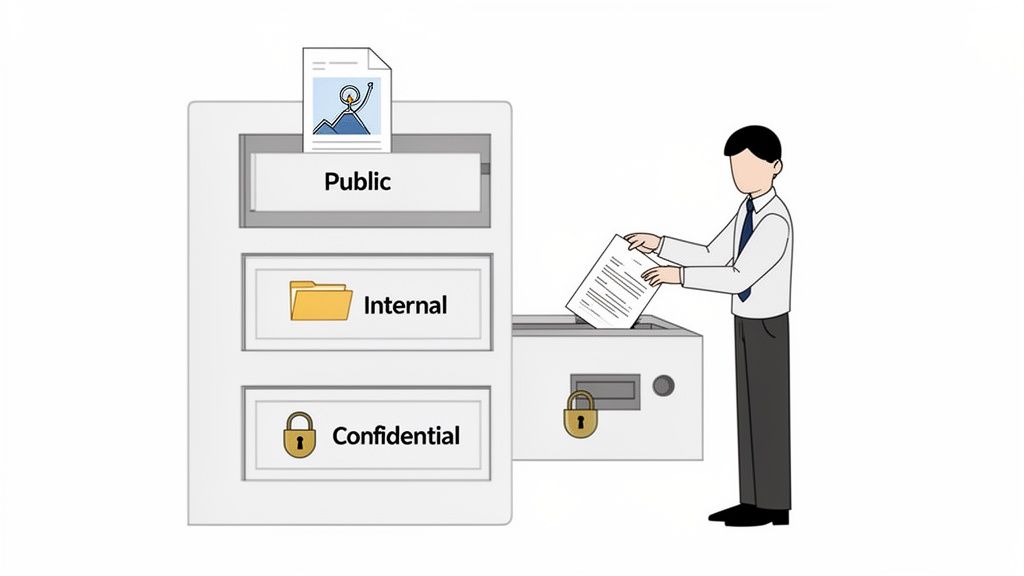
A common and highly effective approach uses three primary levels: Public, Internal, and Confidential. This tiered system is detailed enough to protect critical assets without becoming a burden for employees to follow in their daily work.
While the specific labels may vary, the underlying principles of risk and handling requirements remain consistent.
Core Data Classification Levels at a Glance
This table breaks down a typical three-level classification scheme, providing a clear guide for what each level means and how data should be handled.
| Classification Level | Example Data Types | Primary Business Risk | Handling Guideline |
|---|---|---|---|
| Public | Press releases, marketing materials, public website content, job postings | Minimal risk of unauthorised disclosure | Can be freely shared with anyone, inside or outside the organisation. |
| Internal | Internal memos, team project documents, employee handbooks, operational procedures | Unauthorised disclosure could cause inconvenience or minor operational disruption. | For internal company use only. Should not be shared externally without permission. |
| Confidential | Customer Personally Identifiable Information (PII), financial records, intellectual property, employee records, source code | Disclosure could lead to significant financial loss, reputational damage, or legal penalties. | Must be protected with strict access controls, encryption, and monitoring. Access is on a "need-to-know" basis. |
This foundational work of organising information is a prerequisite for leveraging more advanced technologies like AI and machine learning. To better understand how this enables complex systems, it's worth exploring What Is Data Labeling and Why AI Needs It. Ultimately, understanding and organising your data is the first step toward building scalable, secure, and future-ready business operations.
The Three Pillars of a Strong Data Classification Strategy
Knowing what data classification is and why it matters is the starting point. Building a framework that functions effectively in a real-world business environment is the next critical step. A successful strategy is built on three interconnected pillars: your Approach, your Policy, and your Taxonomy.
Getting these elements right ensures your classification efforts are consistent, scalable, and—most importantly—understood and adopted by your entire organisation. Think of it like constructing a building: the approach is your construction methodology, the policy is your architectural blueprint, and the taxonomy is the clear labelling system for each room.
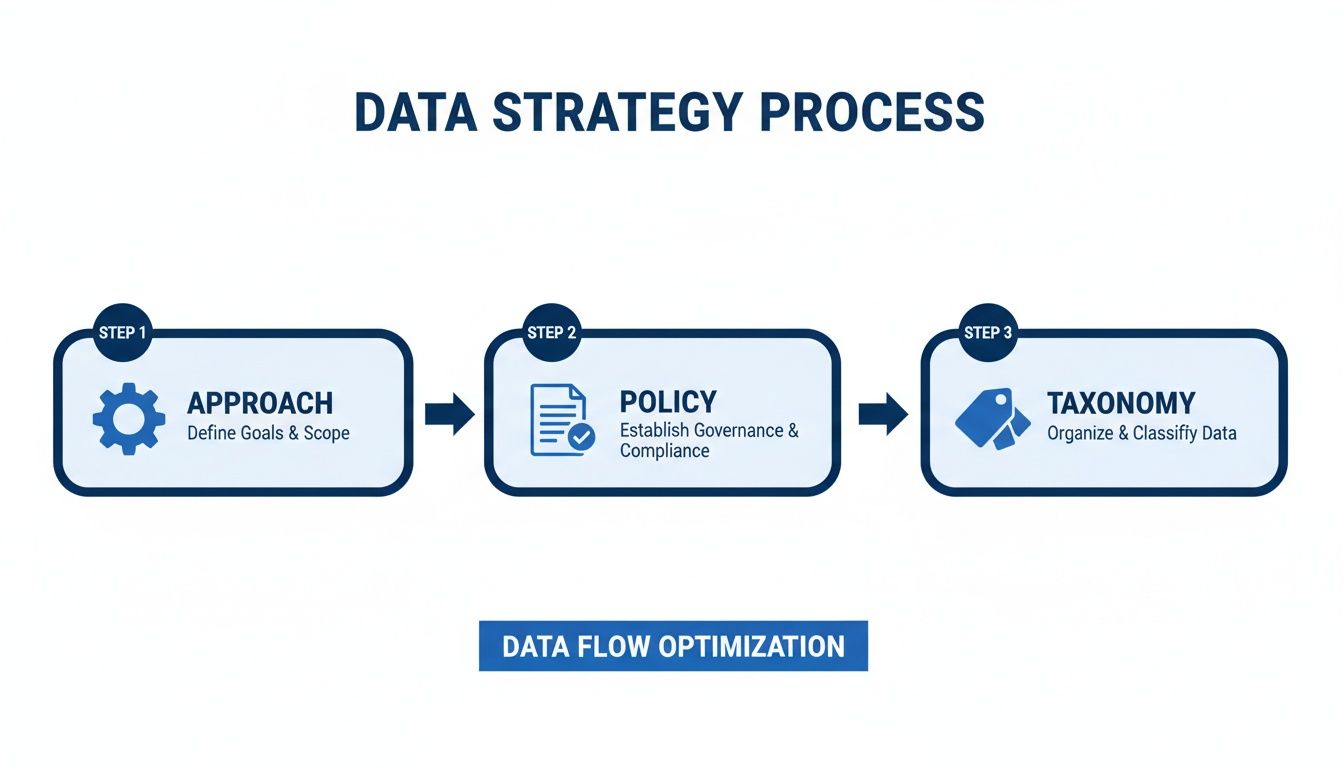
Pillar 1: Choosing Your Classification Approach
The first major decision is determining how classification labels will be applied to your data. There is no single "best" method; the right choice depends on your organisation's size, data volume, risk appetite, and available resources.
The three primary approaches are:
- Manual Classification: This relies on employees to use their knowledge and judgement to apply labels to the data they create and manage. While it leverages human context, it is prone to inconsistency, human error, and subjective interpretation. For a small business with minimal sensitive data, it can be a starting point, but it does not scale.
- Automated Classification: Technology takes the lead, using pattern matching, regular expressions, and machine learning algorithms to scan, identify, and tag data based on predefined rules. It is fast, consistent, and essential for any organisation with significant data volumes. The main considerations are the initial implementation cost and the need for careful tuning to minimise false positives.
- Hybrid Classification: This approach combines the strengths of both methods. Automated tools handle the bulk of the classification, while employees are prompted to confirm or adjust classifications in specific scenarios. This "human-in-the-loop" model often delivers the best balance of scale, accuracy, and user engagement.
For most modern businesses, especially those handling regulated data or operating in the cloud, a hybrid or fully automated approach is the only viable path forward. Relying solely on manual efforts in today's complex data environments is a recipe for failure.
Pillar 2: Defining Your Data Classification Policy
Your data classification policy is the formal rulebook for your entire programme. It transforms the strategy from a high-level concept into a concrete, enforceable corporate standard. This document is not just for the IT department; it provides clarity and guidance for the entire business.
A strong policy is the bedrock of data governance. It clearly outlines the 'what,' 'why,' and 'who' of data handling, creating a single source of truth that aligns security controls with business objectives.
An effective policy must clearly define:
- Objectives and Scope: State why the policy exists (e.g., to comply with GDPR, protect intellectual property) and what data and systems it covers.
- Classification Levels: Provide clear definitions for each level (e.g., Public, Internal, Confidential), complete with practical, real-world examples.
- Roles and Responsibilities: Define who is accountable for what, including data owners, IT administrators, and the responsibilities of every employee as a data user.
- Handling Procedures: Provide simple, direct instructions for storing, sharing, and disposing of data based on its classification. For example, "Confidential data must be encrypted when stored on removable media."
- Enforcement: Outline the consequences of non-compliance to ensure the policy is taken seriously.
This policy is a critical component of your overall security architecture. To understand how it fits into a broader framework, explore established data governance best practices.
Pillar 3: Creating a Clear Data Taxonomy
If the policy is the rulebook, the taxonomy is the simple, consistent language everyone uses to follow those rules. In practice, a taxonomy is the set of labels or tags applied to the data itself. Simplicity is paramount.
An overly granular taxonomy with dozens of labels will only confuse employees and lead to poor adoption. A simple, intuitive set of labels ensures everyone, from an executive to a new hire, can understand and apply them correctly.
A clear four-level taxonomy might look like this:
- Public: Information approved for public release.
- Internal: For use by employees and contractors within the company.
- Confidential: Sensitive data restricted to specific departments or roles.
- Restricted: Highly sensitive data with strict need-to-know access controls.
When this simple language is embedded into systems and daily workflows, your classification policy becomes a living part of the company culture rather than just another document on a server.
A Practical 6-Step Implementation Plan
Transitioning from strategy to a functional data classification programme requires a structured, phased approach. Think of it not as a one-time IT project, but as a continuous business initiative. This roadmap outlines the essential steps, from defining objectives to establishing a cycle of continuous improvement.
Successfully executing this plan requires collaboration across multiple departments. Organisations often get bogged down in the complexity, which is where the guidance of an experienced IT partner can streamline the process and accelerate time-to-value.
Step 1: Define Clear Objectives
Before classifying a single file, you must define what success looks like. Is the primary driver to meet a specific regulatory requirement like GDPR? Is the goal to protect high-value intellectual property, or is it to reduce data storage costs?
The answers will shape every subsequent decision. For instance, a compliance-driven project will prioritise the discovery and classification of Personally Identifiable Information (PII). In contrast, a cost-reduction initiative would start by identifying and eliminating Redundant, Obsolete, and Trivial (ROT) data.
Step 2: Formalise Your Policy and Taxonomy
With objectives defined, the next step is to codify them in your official Data Classification Policy. This document serves as the single source of truth for how data must be handled. Concurrently, you will finalise your simple, intuitive taxonomy—such as Public, Internal, and Confidential—that everyone in the business can easily understand and apply. This phase is about establishing consistency from the outset.
Step 3: Initiate Data Discovery
You cannot protect what you do not know you have. Data discovery uses automated tools to scan your entire IT environment—from legacy on-premises file servers and SharePoint sites to modern cloud platforms like Microsoft 365 and Azure—to locate where your sensitive data resides. This process often uncovers "dark data"—forgotten, unmanaged information in unexpected locations—which represents a significant, unaddressed security risk.
Step 4: Apply Classification Labels
Once sensitive data is located, it’s time to apply the labels from your taxonomy. A hybrid approach is often most effective:
- Automated Labelling: Configure rules to automatically apply a "Confidential" label to any document containing patterns like credit card numbers or sensitive project codenames.
- User-Driven Labelling: Prompt employees to select a classification level when creating or saving new documents, reinforcing accountability.
Tools within the Microsoft ecosystem are particularly powerful for this. In the UK, with over 5.6 million private sector businesses, the sheer volume of data makes manual classification an impossible task. For businesses migrating to Azure, leveraging tools like Microsoft Purview to automate this process is essential for maintaining security and compliance at scale.
Step 5: Enforce Security Controls
A label is just a tag until it triggers a security action. Enforcement is where classification integrates directly with your security controls, setting up automated rules that apply protections based on a file's label.
For example, you can configure rules to automatically:
- Encrypt any email containing an attachment labelled "Confidential."
- Block a user from copying a file labelled "Restricted" to a USB drive.
- Apply a watermark to all documents classified as "Internal."
This step transforms classification from a passive labelling exercise into an active defence mechanism for your most valuable data.
Step 6: Monitor, Review, and Refine
Data classification is not a "set it and forget it" initiative. It is an ongoing programme that must adapt to business changes, new regulations, and data growth. Establish a process for regular reviews to audit classification accuracy, monitor for policy violations, and refine your rules based on real-world feedback. Continuous monitoring ensures the framework remains effective and relevant over the long term.
For a deeper technical guide, see our article on how to implement data classification.
Using Automation to Classify Data at Scale
Manual data classification is simply not feasible for any modern business. The sheer volume, velocity, and variety of data make it an impossible task. This is where automation becomes a strategic enabler, transforming classification from a theoretical policy into a practical, scalable reality. For organisations invested in the Microsoft ecosystem, this is achieved through a powerful suite of integrated tools.
At the center of this ecosystem is Microsoft Purview, a unified governance solution that provides a comprehensive view of your entire data landscape. It moves beyond simple keyword searching, employing sophisticated methods to discover, classify, and protect information wherever it lives—from on-premises file servers to cloud services like SharePoint, OneDrive, and Teams. We cover this in more detail in our guide on how to leverage Microsoft Purview for comprehensive data governance.
This level of automation is what enables a shift from a static policy to a dynamic, intelligent system that scales with your business.
How Automated Classification Works in Practice
The power of automation lies in its ability to identify sensitive data with a precision and consistency that humans cannot replicate at scale. Microsoft Purview accomplishes this through two primary mechanisms:
- Sensitive Information Types (SITs): These are predefined or custom patterns that recognise specific types of data. Purview includes over 100 built-in SITs for common sensitive data like credit card numbers, national insurance numbers, and passport details. A SIT can be configured to not only find a 16-digit number but also validate it using a checksum algorithm, drastically reducing false positives.
- Trainable AI Classifiers: While SITs excel with structured data, trainable classifiers are designed to identify content based on its context. You can train a classifier by providing it with examples of a specific document type—such as a legal contract, a financial statement, or a technical blueprint. The classifier learns the unique characteristics of that content and can then accurately find and label similar documents across your entire organisation. For a great example of how this works in the real world, check out how you can classify large CSV files with LLMs.
This combination of pattern matching and contextual analysis ensures that classification is both rapid and highly accurate.
From Classification to Enforcement
Identifying sensitive data is only half the battle; the ultimate goal is to protect it. Automation creates a seamless bridge between classification and protection. When a file is automatically labelled "Confidential," that label acts as a trigger for security policies managed by tools like Azure Information Protection (AIP).
By integrating classification with enforcement tools, you create an automated security response system. The label itself dictates the rules, ensuring that the right protections are applied consistently without any manual intervention.
This tight integration enables powerful, automated security actions:
- Automatic Encryption: Files labelled "Confidential" can be instantly encrypted, ensuring only authorised users can access them.
- Access Restrictions: Policies can prevent files with a "Restricted" label from being emailed outside the corporate network.
- Watermarking: Documents classified as "Internal" can be automatically watermarked to deter unauthorised distribution.
This automated enforcement is critical for regulated industries. The UK Statistics Authority's Integrated Data Service (IDS), for example, relies on advanced data classification to manage over 100 sensitive public datasets. For businesses adopting Azure OpenAI and Microsoft Copilot, this government-led model demonstrates how critical robust classification is for protecting data in advanced AI environments. By embracing automation, you ensure policies are consistently enforced, reduce human error, and build a data protection framework that can truly scale.
Common Pitfalls and How to Avoid Them
Even with a well-defined strategy, data classification initiatives can encounter significant challenges during real-world implementation. Shifting from a policy document to a living security framework requires navigating common—and often costly—mistakes. Success often depends on understanding these challenges and proactively addressing them from the outset.
Many organisations fall into the trap of treating classification as a one-time, purely technical project. This mindset inevitably leads to a system that is outdated and irrelevant almost as soon as it is launched. Effective data governance is not a task to be completed; it is an ongoing business process.
Pitfall 1: Overly Complex Schemes
One of the most common mistakes is creating a classification system that is too complicated. When employees are faced with ten different labels, each with subtle distinctions, they are likely to either ignore the system entirely or apply labels arbitrarily. In either case, the value of the programme is lost.
Solution: Start with a simple, intuitive framework. For most businesses, a three or four-level system is sufficient:
- Public: Information that can be shared with anyone.
- Internal: Data for use within the company.
- Confidential: Sensitive data restricted to specific teams.
- Restricted: Critical data with the highest level of control.
Simplicity drives adoption and ensures consistency across the organisation.
Pitfall 2: Lack of Leadership Buy-In
A classification initiative launched without visible support from executive leadership is destined to fail. If employees perceive it as "just another IT mandate," it will not be taken seriously. Without executive sponsorship, securing the necessary budget and cross-departmental cooperation becomes an uphill battle.
Solution: Build a strong business case focused on risk reduction and compliance. Frame the discussion around protecting the organisation from financial losses, reputational damage, and legal penalties. When leaders understand the "why" behind the initiative, they will become its most effective champions.
Treating data classification as a continuous process rather than a one-off project is fundamental. Data is constantly being created and modified, so your classification efforts must be dynamic to remain effective and provide lasting value.
Pitfall 3: Forgetting the Human Element
Many programmes fail because they overlook the people who create and handle data every day. Rolling out new tools and rules without a comprehensive communication and training plan is a recipe for poor adoption. If your team doesn't understand their role or why classification matters, even the most advanced technology will be ineffective.
Solution: Invest in a communication plan that educates users on the importance of their actions. The public sector offers a strong model here; bodies like the ONS meticulously classify data to provide clear, standardised insights. Businesses moving to Azure can learn from this structured approach to both secure data and manage costs. You can learn more about their statistical analysis of degree classifications to see this in practice. This disciplined mindset aligns perfectly with a Zero Trust security model, ensuring robust and consistent data governance.
Making Data Classification a Business Advantage
To be clear, understanding what data classification is goes far beyond a compliance exercise or a technical control. It is the strategic foundation for a secure, efficient, and forward-thinking business. When implemented correctly, classification transforms the abstract concept of 'data' into a well-organised, visible, and actively protected corporate asset.
The journey begins not with complex theory, but with practical action: a clear, simple policy and taxonomy that your entire team can understand and support. From there, leveraging automation with tools like Microsoft Purview is what turns that policy from a static document into a dynamic defence that scales with your business.
From Technical Task to Strategic Enabler
The benefits extend well beyond security. A mature classification framework streamlines operations, reduces storage costs by identifying redundant data, and provides the visibility needed for confident decision-making. It enables you to adopt new technologies securely and meet regulatory demands proactively, not reactively.
Think of data classification as the central nervous system for your modern data governance. It connects your security controls, compliance duties, and operational processes, making sure they all work together to protect and add value to your most critical information.
Achieving a mature state of data governance, particularly when dealing with legacy systems or a complex cloud migration, can feel like a monumental task. The challenges of data discovery, policy creation, and tool integration often require specialised expertise to execute efficiently.
This is where strategic guidance can make a significant difference. Partnering with specialists who have architected and implemented these frameworks can accelerate success, helping you avoid common pitfalls and build a scalable data governance programme that is prepared for the future. By taking a structured, experience-driven approach, you can transform data classification into a sustainable business advantage.
Frequently Asked Questions About Data Classification
When businesses begin to explore what classifying their data entails, several common questions consistently arise. Addressing these clarifies the practical aspects of implementing a successful data classification programme.
How Does Data Classification Help with GDPR Compliance?
Data classification is the bedrock of any GDPR compliance strategy. The regulation requires you to know what personal data you hold, where it is stored, and how it is protected.
By classifying your data, you can systematically identify and tag all information that qualifies as Personally Identifiable Information (PII). Once this data is labelled, applying the necessary safeguards—such as encryption, access controls, and retention policies—becomes straightforward. This provides a defensible and auditable record of your compliance efforts.
Can We Classify Existing Data or Only New Files?
A common misconception is that classification only applies to newly created data. To be effective, a strategy must cover both historical and new data. The process typically begins with a comprehensive discovery phase.
Automated discovery tools are designed to scan your entire data landscape—old file servers, databases, and cloud storage—to find and apply classification labels based on your rules. At the same time, that same policy gets applied to every new file as it’s created or changed, giving you complete and ongoing control.
How Long Does a Data Classification Project Take?
The timeline depends on the size and complexity of your organisation's data landscape. While there's no one-size-fits-all answer, a phased approach is almost always the most effective strategy. Instead of attempting to classify everything at once, successful projects prioritise the most critical data first.
- Phase 1 (Initial Rollout): This phase focuses on your most sensitive data, such as customer financial records or key intellectual property. This initial stage can take from a few weeks to a couple of months.
- Ongoing Process: After the initial phase, the programme is expanded to cover other data domains across the business. It's vital to view classification not as a project with an end date, but as a continuous programme that evolves with your business.
This methodical approach delivers immediate risk reduction and builds momentum for the broader initiative.
Navigating the complexities of a data classification project, from policy creation to technology implementation, requires careful planning and expertise. Organisations often rely on structured IT support to build a scalable and secure data governance framework that is ready for the future. Book a free consultation to start building your plan today.